Upgrading/restoring a large PostgreSQL database
Posted on February 27, 2018TL;DR: Restoring large tables in Postgres is much faster, if you add the indexes and constraints after the data.
In my spare time I’m trying to help out at a project called OpenSNP, which is an open-source platform that lets you upload your genetic data, downloaded from certain proprietary platforms, connects it to the relevant research and provides it to other researchers, not connected to said platforms. Each of those uploaded files, called a genotype, contains between 0.5M and 1M rows, each of which we parse and store in Postgres. Each of the rows contains a so called SNP (“snip”), or single-nucleotide polymorphism, which you can imagine as your genetic configuration parameters, the values of which, if you like me are not a biologist, may recognize from biology class: the base pairs made up of adenine, cytosine, guanine and thymine. Also, the documentation for that configuration was never written and researchers are only slowly trying to reverse-engineer it with the help of genome-wide association studies.
The Data
In Postgres this data is kept in three tables: genotypes, which contain the
references to the files and to the users, snps, which contains information
related to each of the SNPs, and user_snps, which contains references to the
genotypes, the snps and a two-letter string for the base-pairs, one row for
each of the rows in each of the genotype files.
+-----------+ +-----------------+ +------+
| genotypes |--<| user_snps |>--| snps |
+-----------+ +-----------------+ +------+
| user_id | | snp_name | | name |
| file | | genotype_id | | ... |
| ... | | local_genotype* | +------+
+-----------+ +-----------------+
* a.k.a. the base pairAs of this writing, the database contains 4118 genotypes and 1.3B user-SNPs,
which is by far the largest table and the only one that ever creates problems
in terms of time it takes to insert data into it. Importing a new data set (the
0.5M to 1M rows mentioned earlier), currently takes about 2 hours on average.
Most of that time is spent updating the indexes, without indexes inserts are
near-instantanious. The whole database amounts to about 210 GB, including
indexes. There is a primary key on the user_snps on genotype_id and
snp_name and an additional index on snp_name as well as a primary key
constraint on the genotype_id.
snpr=# \d user_snps
Table "public.user_snps"
Column | Type | Modifiers
----------------+-----------------------+-----------
snp_name | character varying(32) | not null
genotype_id | integer | not null
local_genotype | bpchar |
Indexes:
"user_snps_new_pkey" PRIMARY KEY, btree (genotype_id, snp_name)
"idx_user_snps_snp_name" btree (snp_name)
Foreign-key constraints:
"user_snps_genotype_id_fk" FOREIGN KEY (genotype_id) REFERENCES genotypes(id)Migrating the data
When migrating the database to a new machine, we decided to migrate from
Postgres 9.3 to 9.5, as this is the version that ships with the latest LTS
release of Ubuntu. I tried migrating the data using pg_upgrade at first, but
after a few days it became clear, that this would take longer than expected. It
slowed down quite a bit over time. I manually kept track of the size of
Postgres’ data directory now and then, using a Google Sheet.
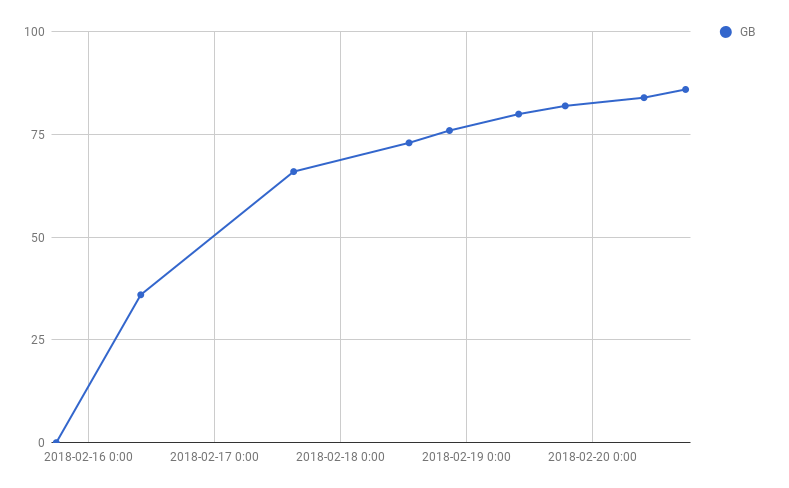
For what it’s worth, Google Sheet’s FORECAST function estimated it to finish
in just under a year. 😬
The only reason I could come up with, for it to get slower over time, was that
it must be updating the indexes as it inserts into the user_snps table. I
vaguely hoped Postgres’ COPY function would copy the data first and re-index
afterwards instead, but evidently it doesn’t. Since we didn’t want to wait a
whole year, I aborted the mission and started over. This time, in order to
avoid this problem, I took separate dumps of the original database, one in
text-format for the schema, one in custom format for the data:
pg_dump --schema-only -Fp snpr > snpr-schema.psql
pg_dump --data-only -Fc snpr > snpr-data.psqlI opened the snpr-schema.psql and commented out the indexes, and while I was
at it, the foreign key constraints, of the user_snps table. I restored the
schema and the data on the new machine and ran the commented out bits after the
data was imported. The whole process only took a few hours. Unfortunately, I
don’t have a graph or an exact time for that. I ran it overnight and it was
done the next morning.
Conclusion
When restoring a large Postgres database, import the data before the indexes. The next time I’ll try writing a script for that, unless someone else does it first (*hint*) or it already exists. Additionally, always keeping track of long running processes is a very good idea. Without keeping track of the progress of the import, we wouldn’t have been able to make an informed decision on whether to abort or not. Even better is having a script in place doing that for you, e.g. logging the size of Postgres’ data directory to a file every minute, or have monitoring in place on the machine, keeping track of the disk usage.